
Handling System Design Questions in Technical Interviews
Category: Self Improvement
Tags: Interviews
The first thing to understand is that design problems focus on higher-level aspects than coding problems. Because we are not going to the implementation level, the problem can have a much larger scope. By contrast, coding problems are usually narrow in focus by necessity given the time constraints. The purpose of a design-level question is to get a sense of how you solve larger-scale problems.
If you are asked to create a design for a given problem, focus on the most important design decisions that need to be made. You typically don’t need to go into detail about the object model and all its attributes. However, you would need to discuss any attributes that are significant to the overall design. In the navigation system example, it was relevant to point out that each node in the graph stores the latitude and longitude. Why is this important? Because our search needs to start somewhere, and given a starting point for navigation, we need a way to find the closest node in our graph.
Another example would be a system design that involves messaging. Does the message contain all of the relevant information, or does it have pointers to the information? A common use case for messaging is to communicate to other systems when some data has changed. The two basic options then are:
- The new or modified data is contained in the message itself
- The message has the identifier for the changed data, perhaps along with a version number or timestamp. It is the responsibility of the consumer to go retrieve the updated data.
This choice would be an appropriate level of detail to discuss when describing the solution. It demonstrates that you have a good understanding of the types of issues and considerations involved when implementing messaging-based solutions.
When beginning to answer design questions, talk through the following:
- What are the key requirements? This could include both functional and non-functional requirements. A non-functional requirement is a system-level requirement, such as transaction throughput or performance requirements.
- What are any assumptions we need to make? * What are the key challenges we will face?
When discussing the design solution, consider the following:
- What are the main components you would use to implement the solution?
- What are the main data structures or algorithms that are needed?
- What are the primary technologies you would use to implement the components?
Design Patterns
Good software engineers understand they don’t have to reinvent the wheel all the time. Senior engineers are able to identify patterns that reoccur in systems. Many problems that you encounter will have already been tackled by someone else. Patterns are used to capture the solutions to these recurring problems.
There are two levels of patterns:
-
Architectural patterns: This includes the use of service-oriented architecture, microservices, and event-based architectures. The use of messaging and enterprise integration patterns are also included in this category. A seminal book in this area is Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions (2004) by Gregor Hohpe and Bobby Woolf.
-
Design patterns: These classically refer to lower- level object-oriented design patterns in your system that influence the object model and interfaces between classes. The “Gang of Four” book is a seminal work in this area. It is called Design Patterns: Elements of Reusable Object-Oriented Software (1994) written by Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides.
Many design questions can leverage architectural patterns. Lower-level design patterns may also be used to answer the question if there are critical components that need elaboration in order to demonstrate an understanding of the solution.
Other systems design questions will be focused on object-oriented design. For these, you will use your modeling skills as well as patterns from the Gang of Four book.
Perform your best in technical interviews
A step-by-step guide to prepare for your next interview

Architectural patterns
Many system problems take the form of the funnel pattern shown in the figure below. Numerous input events are funneled into the system for processing. These events may originate within the application, such as users clicking buttons in the interface, or they may originate from remote systems or devices. However the events originate, they are sent through a central processing pipeline. The output from processing is typically stored and used in a number of different ways. The overall design looks like a fan-in through a central conduit followed by a fan-out of data and processes.
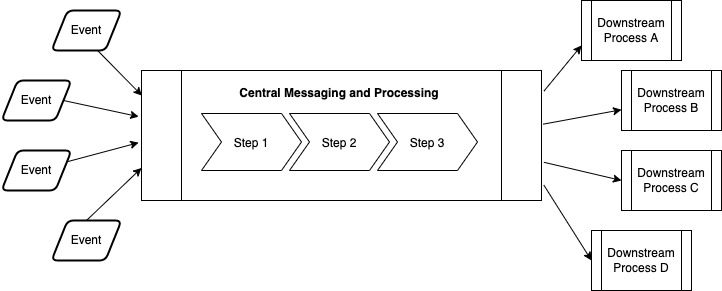
Let’s look at a few examples. Consider the design for a social media system like Twitter. Users can tweet messages from their phones or computer. These input events are sent through a process that filters them for any content violations, indexes them in applicable data stores, and stores them. Subsequent algorithms are used to determine what users should see what tweets. The trending tags and tweets are updated accordingly. Users reading their Twitter feed will see the latest tweets from people they follow and other tweets that the algorithm thinks will be of interest.
A news feed application would follow a similar pattern. Stories are written and submitted, or aggregated from various sources such as the Associated Press or Reuters. The latest stories are the input events to the system that get processed. Similar to the Twitter example, story events are processed and filtered for various users to view in their news feeds. Additionally, the processor may determine whether notifications are sent to particular users.
A web crawler scenario uses a similar pattern, albeit with one major difference. It requires a component to go seek out and create the input events. It does this by scanning the web for new or updated pages to index. In a design scenario like this, the crawler component is the key challenge. There are numerous websites that cover this design question if you want to dive deeper into it.
Microservices
Systems are often decomposed into services. In the real world, services often mirror the organizational structure. Services that perform relatively small scope functions are called microservices. By nature, a microservices architecture requires a decent number of services to enable coarse-grained capabilities.
One consideration with service-oriented architectures is a high degree of inter-dependencies between services. Service mesh frameworks can be used to help simplify the operations of these architectures.
Each new service that is introduced adds the possibility of failures and retries. Distributed systems are very powerful, but they can be operationally complex as well. AWS as a platform is itself a set of services that build upon each other to provide capabilities. For example, CloudWatch is a fundamental service used by almost every other AWS service. Likewise, almost every service runs within a VPC, another fundamental service.
If you are interviewing for a senior engineer or architect role, then it is important to understand the pros and cons of service-based architectures. Perhaps the greatest strength is that it unblocks each team to control their own destiny and launch new capabilities as rapidly as they can. Consumers can upgrade or use the new capabilities when they are ready. Service-oriented development is great for rapid innovation.
When you are working through a design problem, consider if breaking out some capabilities into services would be helpful. If a function is generally useful across a number of use cases or systems, a service mechanism provides a great way to reuse the capability.
Event-based architectures
The general funnel pattern is itself an event-based architecture. An implementation decision to make is how to process events. The most common choice would be to send events through a messaging framework. Subscribers read messages and process them as they come. AWS SQS and Lambda provide this capability.
The advantage of this approach is that it scales up quickly at peak times when there are many messages. One disadvantage is that you don’t control the order of events coming in. Designs also need to factor in that different nodes end up processing different events. Thus you need the ability to handle each event independently. There are some use cases where this constraint poses a problem, as we will see in the next chapter.
If you need more control over input events, another option is to store events in a database table. This allows greater control over what events to process next. You can select events to process based on priority, timestamp, status, or any other attribute that you define. This design typically uses a state machine to control the flow.
State machines
A state machine is simply a defined workflow where entities go from one state to another using specific processes. Only valid state transitions are allowed, and specific software functions are used to proceed between states.
Consider the news feed use case. Each time the crawler finds a new or updated web page, it creates an entry in the crawler_workflow table with a state of NEW.
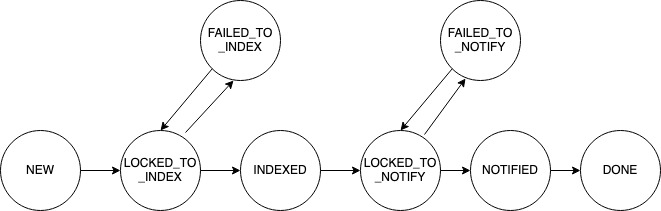
One process runs periodically to query the table for rows with a status of NEW. It updates the status to LOCKED so other processes don’t perform the same work. It retrieves the news story, stores it in the data store, and adds it to the index. If this is successful, it updates the row to be INDEXED. Otherwise, it sets the status to FAILED_TO_INDEX.
Another process looks for INDEXED rows to lock so that they can perform the notification logic. This component decides what users should be notified of this new story. Once that is successfully completed, the overall workflow is DONE.
A separate sweeper job is used to remove older DONE rows. It also retries jobs in the two failed statutes as well as rows that are “stuck”, meaning they have been in a locked state longer than a given threshold amount of time. Typically you would include a last updated timestamp and a retry count to manage failures and retries. If a job surpassed the retry count, the on call support technician would likely need to investigate and see what persistent issue is causing the failure.
Data architecture
In distributed systems, it is important to understand data entities should have a well-defined system of record. This is the system that is the authority for updating the information and is the definitive source if you need the absolute latest state available. Data is often passed around between systems, so if your system gets data from somewhere other than the system of record, be aware that it could be out of date.
Most enterprise data architectures have three layers. The first is the transactional data store that lives within each application. This is the database that the application server talks to and uses to manage the state of business entities. These are typically the systems of record.
The second layer is made up of operational data stores. Not every organization will use these. If they are used, it likely is a larger organization or one that deals with large volumes of data. The purpose of an operational data store is to integrate data from multiple sources to support both strategic and tactical decision-making as well as integration workflows. It can feed data into the data warehouse.
Some organizations go directly from transactional data stores to data warehouses. This is where business analytics and reporting run against a central place. Extract, Transform, and Load (ETL) jobs are typically used to populate data warehouses.
Another aspect of database architecture is the concept of primary and secondary nodes. The primary node of a relational database is the one place where writes or updates need to go. Data can then be replicated to secondary, or read-only, nodes to increase the scalability fo read operations.
Most application servers or containers have mechanisms where the application specifically asks for a read-write connection or a read-only connection. Whenever possible, the read-only connection should be used so that the overall throughput of the database can be maximized. The downside is that an application component using the read- only connection needs to be able to handle the case where it gets stale data. At the moment a transaction is committed on the primary node, the read-only node could provide data that is slightly out of date prior to it being replicated. Your use case’s requirements will dictate when a consistent read is necessary.
Object Oriented Design
Many of the object design patterns are similar to each other. There are only a few you really need to know. The key creational pattern is the factory method pattern. Based on the input parameters, the specific subclass or implementation type is returned although your client can be ignorant of those details. It just knows it is getting an implementation of the requested interface or service.
The Mediator and Facade patterns are structural patterns you should be familiar with. These are relatively straightforward in that they represent a logical “service”. By this, we mean that they implement a workflow and use other objects or services within its implementation to perform the work. They isolate the client from knowing the details of how the service accomplishes its work.
A key behavioral pattern to understand is the Strategy pattern. This pattern might be used within a Mediator or Facade when there are different implementations of the same goal based on the input parameters or state of the data. The Strategy encompasses how to do something without the client needing to understand the details. Patterns like this help avoid a lot of nested if statements and make the code more reasonable and reusable.
In terms of reuse, inheritance and composition are two structural options. Keep in mind that inheritance can be fairly brittle in terms of reuse. If the structural relationship changes much, it can make code changes messy. However, if you have a well-defined template for how to do something, the Template Method pattern is a solid choice. In this pattern, the parent class has a method that does the work. The fundamental notion in this pattern is that some methods within this template are implemented differently by subclasses.
The Visitor pattern is a good pattern to know when dealing with graph data structures.
Design tips and tricks
Being able to reason through problems is more important than getting the one, single best answer or correct solution. So don’t stress if an ideal solution does not come to mind right away. Take your time and work through it. Think out loud so the interviewer gets a feel for your thought process.
Many interviewers will give hints. This is analogous to being at work and getting guidance from a senior engineer. Given some direction, can you then solve the problem? It doesn’t mean you are doing badly if you are given a hint.
Don’t be afraid to ask clarifying questions. This is really important. This shows that you understand requirements analysis and pay attention to detail. Sometimes interviewers will give intentionally ambiguous questions or problems. It is better to ask than make the wrong assumption.
Perform your best in technical interviews
A step-by-step guide to prepare for your next interview